Seven guiding principles of serverless systems
- Nikody Keating
- Jun 15, 2021
- 8 min read

Updated: Jul 29, 2021

The big question in serverless design is how do you know your team is doing it correctly? Serverless can feel fuzzy, and best practices don't feel so obvious. The repercussions of an inexperienced team can lead to project deadlines being missed, your system randomly breaking without the team understanding why and security risks that can't easily be mitigated. The good news is that there are some fundamental principles that can help you navigate your journey.
Principle 1: Use a serverless framework
While your IT team could manually deploy all of their components in aws, or use terraform or cloudformation, the amount of knowledge and groundwork to make it work can be daunting. Instead, use a framework like AWS SAM and the Serverless Framework. These frameworks provide better development and deployment experiences for your IT team, and simplify the concepts like security that are underlying concepts in AWS.

If you want to jumpstart your team in these frameworks, there are also tools out there like Stackery, which simplify creating resources the programming templates to dragging, dropping and connecting AWS resources visually. Stackery also has the benefit that they cover four aspects of your software development life cycle: Environment Setup/Configuration, Deployment (CICD capabilities), Design Documentation (Visualization) and local development/debugging.
Principle 2: Use services, not code
Your IT team should only focus on writing components which are specific to how you do business. Instead of writing systems, your teams can use services which solve a lot of the technical computer science technical problems. This means your team starts focusing on combining capabilities of these various services and trim their code down to the logic of how your business operates.
Take, for example, security concerns like SQL Injection, which can wreak havoc on a database. AWS has a component called a Web Application Firewall (WAF) that already has rules to scan for attacks like this and block them. There are components for ensuring that communication to partner's systems will wait for those systems if they go offline. There are even components for permission based access to data through an API. Your IT team can put less effort into programming and more effort into writing new capabilities for your business.
Principle 2.1: Relational databases are an afterthought

While we could consider this an extension of Principle 1, I believe it needs to be emphasized as it's a big departure from what teams are used to. Your team is probably used to writing code for your more traditional databases. When looking at the effort it takes to build, optimize and maintain these databases, we must ask is it worth it for most scenarios.
For most applications, the database is a place to store and retrieve information. Since traditional databases can't store data in the same structure the program uses it, the IT team must write even more code. This is a lot of effort for just storing and retrieving information.
Here's where NoSql databases such as DynamoDB come into play. NoSql databases can store information in the same structure the application creates and uses it in. This reduces the effort the IT team goes through by 30% - 40%. This time gets put back into building business capabilities.
Where you need to perform ad hock queries against data for business intelligence reason, consider using your data warehouse. DynamoDB streams can propagate data real time to data warehouses, allowing your data warehouse to provide insights and analysis to information that is in flight. This approach converts the data once, with the consumer being a relational engine, rather than requiring applications to perform the conversion in order to use the data.
Principle 3: Immediate processing unless impossible
Serverless systems become simpler when processing is immediate, real time or immediately asynchronous. Something mostly forgotten the concept of over burdening servers as your systems scale infinitely in their serverless design. The nice thing here is that customers and business partners typically like immediate processing systems. It reduces the cost of business processes, it improves the relationships with customer and more.
IT teams have dealt with large amounts of data in a traditional system by queuing up work and process it all at a specific point in time, also called batch processing. This approach is to ensure that the volume of requests does not overburden the processing system. In serverless, while there are optimizations for performance, the concern about getting more processing power isn't a limiting factor for design.
The result is, it's simpler to create immediate processing for IT teams and the compute power for serverless eliminates the concerns around overburdening the system. That said, there still are business reasons for non-real-time processing. An example of this is where you have a commissions contract where the company that owns the commission at the end of the month gets the commission. If the commission contract where to change hands mid month, an immediate processing system could attribute commissions to the wrong party. This is an example of an exception to the imediate processing rule.
Principle 4: Use processing everywhere
One of the biggest changes to website development was the creation of frameworks like Angular and React. These frameworks use your customer's browsers and processors to create dynamic, responsive and speedy experiences. The concepts behind it come from some of the best practices around software development as well. The good news here is that you now have a free source of processing power at your potential, which immediately scales to billions.
While there are some things that you might want to keep proprietary the way your user interface lays out isn't one of them. Customers and hackers can easily deduce meaning and process from visual queues you provide, so we should not consider sending the data necessary data to create visuals proprietary either. Often, depending on your customers and the level of trust they have, you can even use processing power to do basic calculations, removing things like sums and summary calculations from the backend processing.
Principle 5: Monitoring
Monitoring for serverless systems is extremely important, and the right solution can allow you to investigate issues in your systems faster and get fixes deployed quickly. The big difference to your IT team with serverless is the transition to a micro-service architecture. There are a lot more logs that have to be matched up in order to understand what happened when errors occur. The best type of solution for this problem is Tracing. Tracing solutions, like Epsagon, map out all the interactions across your system, and your IT Team can more effectively follow a call from your customers all the way through the system and find the point where the system breaks down. These solutions also provide health dashboards, which can highlight unstable parts of your system.
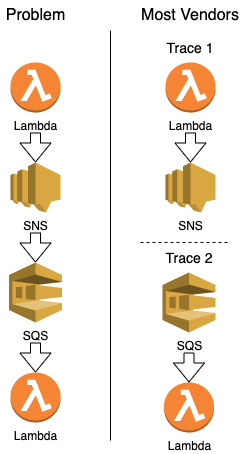
When evaluating tracing vendors, one question you should ask is "How is your handling of complexity in tracing". One test I give is asking, "What happens in their system if I have a Lambda call an SNS Topic which has a message en-queued in SQS which is received by another Lambda". 95% of vendors cannot handle this situation at this point. This is one of the primary reasons I recommend Epsagon. While this scenario doesn't come up often, the ability for the company to stitch together traces for you for this problem often means they understand how to work with more than just instrumenting your code, but leverages other AWS services to help resolve direct interactions between services. The result is that your team is putting less effort into investigations and more effort into finding and fixing issues quickly.
Principle 6: Redundancy and recovery
Serverless systems tend to inherit redundancy and tolerance to data center failures. This makes ensuring availability is simple. What your IT team needs to ensure is that when you are dealing with systems which aren't serverless or are outside of your control, such as a document printing service, your team considers that those other systems could experience outages and instability. Knowing that, it is important to build a tolerance for failures in other systems. The good news is that services are available to make this process simple, such as SQS.
Unlike more traditional systems, where large disasters are weighed against the effort to maintain and the cost vs. recovery time. Several strategies have been designed to get around the cost vs. time issue including: Backup and Restore, Pilot Light, Warm Standby and Active/Active. Serverless plays by different rules. Setting up for a larger system impact is much easier as services help fill in the gaps and reduce complexity. For example, if your team is using DynamoDB, then use global tables to propagate data to another region continually with minimal latency. You then provision serverless components which don't incur cost unless used in that region. Finally, complete configuration of the second region with secrets for credentials and connection details, as it will not significantly affect your budget. In fact, having two regions actively being used is only slightly more effort than having one region used, and tends to be cost neutral.
Principle 7: Security is still king
In the modern age of business, security is front and center in the minds of everyone. The number of ransomware attacks are increasing, amateur hackers are getting access to systems that should be extremely secure, and it's only going to get worse. While there are security services out there your team can use, it's always best to ensure you're doing your best to ensure that you are making secure systems.
The biggest mistake in this area is granting too much access to your systems, often referred to as "*" access. This should be one of the 7 deadly sins of serverless computing. Teams run into this when they're not experienced or disciplined enough on access management. The typical reason given is, "I don't know what access I need so I will give all access". I've seen code released to production that has given lambda functions unlimited access to the AWS Account, to specific services such as DynamoDB, unlimited actions on Lambda and various others.

So why is this a problem? It is theoretically possible to have Function as a Service (FaaS) turn into a Virus as a Service (VaaS). If your FaaS has enough access, it can create other lambda functions, ransomware your DynamoDBs, grant other accounts access to your account's resources and make it extremely difficult for you to clean up the mess as the VaaS propagates to various regions to avoid detection and increase the effort to remove it. In other scenarios, the lambda function could start removing pillars of your architecture, deleting databases, queues, streams, etc. Repairing these components could take more time and cause significant outages with your system or capabilities within your system.
Having an expert available to your team on permissions management is a must have in the modern age, especially with the amount of ransomware attacks taking place. You should review permissions and changes to permissions as part of the development and release process. If possible, automate rules that ensure general over-provisioning doesn't occur.
Conclusion
Using these six principles, your can evaluate your team's systems and identify where there is room for improvement. Following these principles, your enterprise systems can easily help you increase your speed to market, your readiness for audits and your ability to provide your customers and internal users the best possible experience.
These principles also align with the 5 Pillars of the Well-Architected Framework, which is a good reference for how you can provide an environment of innovation and quality to make your cloud and teams successful.



Comments